Data Storage Algorithms
The method of structured storage takes over all these questions. It appeared in the 1980s, but there has been a recent increase in the use of this method as a method of storage in databases. In its initial application of the file system, it suffers from certain deficiencies that prevent widespread proliferation, but as we see it, they are not so important for the DSB, and a structured warehouse magazine has added value to the database.
The basis for the organization of a structured data repository system, as the name indicates, is a magazine, that is, everything is done through a consistent recording of data. Every time you have new records, instead of finding a place for him on the CD, you just add it at the end of the magazine. Data induction is done by processing metadata: metadata is also updated in the journal. This may seem ineffective, but on the disk of index structure, B-derives tend to be very broad, so the number of index knots we need to be updated with each record is usually very small. Let's see a simple example. We will begin with magazines containing only one data element, as well as the node index, which refers to it:
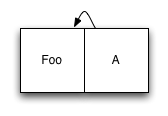
It's okay. Now let's say we want to add a second element. We add a new element at the end of the magazine and an updated version of the index:
The reference record with the index (A) is still in the file, but it is no longer in use: it has been replaced by a new entry A', which relates to the original copy of the Foo, as well as to the new recording of Bar. When you want to read from our file system, we find an index of the root node and use it as it would be in any other system.
Rapid search for the root index. With a simple approach, you could just look at the last block in the magazine, because the last thing we write is always the root index. However, this is not ideal, as it is possible that at the time of reading the index, another process adds to the middle of the magazine. We can avoid this with a single block, say, at the beginning of the magazine, which contains an index to the current root knot. Every time we update the magazine, we'll rewrite the first record to make sure it points to the new root knot.
Next, let's see what happens when we update the element. Let's say we change the Foo:
We started recording a completely new copy of the Foo at the end of the magazine. Then we updated the nodes index (only in this example) and also recorded it at the end of the magazine. Once again, the old copy of the Foo remains in the magazine, but the updated index just doesn't refer to it anymore.
You must have realized that this system is not sustainable indefinitely. At some point, old data will just be in space. In the file system, it's seen as a ring buffer, a retrieval of old data. When that happens, the data that remain in force is simply added to the magazine again, as if they were just recorded and not the necessary old copies will be rewritten.