Data Storage In Tables
 Until recently, all DSBs with structured data (and not only them) could be divided into two categories: the stored records in the design format and the stored records in the column format. This is a fundamental difference that affects how the tables look at the level of internal storage of the CBD. For a long time, CBD Teradata had been assigned to the first group, but with the 14th version it had been possible to determine how to store the particular table in columns or lines. Thus, hybrid storage has emerged. In this article, we want to describe why this is necessary, how it is realized and what benefits it offers.
Until recently, all DSBs with structured data (and not only them) could be divided into two categories: the stored records in the design format and the stored records in the column format. This is a fundamental difference that affects how the tables look at the level of internal storage of the CBD. For a long time, CBD Teradata had been assigned to the first group, but with the 14th version it had been possible to determine how to store the particular table in columns or lines. Thus, hybrid storage has emerged. In this article, we want to describe why this is necessary, how it is realized and what benefits it offers.
What is Teradata Columnar?
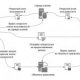
Before we talk about the storage format of the columns, say a few words about how we usually store the row data. We'll take a reference table with columns and lines:How do we write this table on the disk if it's structured? First, write the first line, then the second, third and so on:
 How do we minimize the pressure on the disk system when reading this table? Different methods of access can be used:
How do we minimize the pressure on the disk system when reading this table? Different methods of access can be used:
- Access to the index - if only a few lines are to be read.
- Access to separate Parties (Sections) - if the table is very large (e.g., transactions over several years, but data need to be read only in the last few weeks). It's a string party.
- Full reading of the table if you need to read a large percentage of its lines.
So the minimization of the disk system load is based on the fact that we need to read not the whole table, but only the individual lines.
What about the column? If SQL-request uses not all the table columns, but only some of them? When we read the lines, we read each line completely. If only five of them are needed in table 100 columns and the specific SQL request, we have to read 95 columns that SQL doesn't use.

This breakdown of the table on the columns creates colonies♪ If only separate columns are needed, we're reading only the required parcels from the disc, significantly reducing the number of entry and retrieval operations on the reading of the SQL demand.
The interesting feature of such an approach is that the buoyancy and the colony parties can be used simultaneously in the same table, i.e., intra-participation. First we go into the right parcels, then we read only the right rows.
In sum, Teradata Columnar is a method. Data storage in DSB Teradata, which allows the tables to simultaneously use two Partitioning Methods:
- Horizontal parties - line
- Vertical parties - columns
 Teradata Columnar
Teradata Columnar
Benefits:
- Increased demand productivity - by reading only individual column parties, excluding the need to read all data in the table lines. That's exactly why we started our article.
- Effective automatic compression of data using automatic compression. And this is an additional pleasant opportunity that can be opened when the column data are stored: in this case, the data are much easier to compress. Some even put this advantage at the top, and it is well-founded.
Both paragraphs reduce the pressure on the disk system. In the first case, we read a smaller number of data, so there is a smaller number of input-outs. In the second case, the table occupies less space on the disk and, as a consequence, fewer entries are required to read it.