Data Storage Systems And Server Pools

Virtualization of data storage systems is a full part of the overall virtualization of access, applications, LOs, processor and networking. However, it is with the virtualization of storage that today is probably the most vocabulary, the substitution of the subject to the object, the causes of the investigation, methods, objectives and other purely understandable non-subsidiaries. We'll try to figure this out.
According to the basic definition, virtualization is the abstraction of resources from the real means of providing them. The most important thing to be determined is that virtualization is only a method that provides a convenient form of supplying resources to a certain part of the line upon the request of its other constituents. And this method is typical of open systems. The open system is a complex composed of closed (incamped) blocks between which standard exchange interfaces exist.
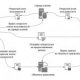
Accordingly data storage virtualization This is the provision of a resource for the physical capacity of the reservoirs in the form of a logical storage space. The true structure of the storage system is encapsulated from the outside environment. Server (host) is exempted from the need to know where and how the data are physically stored, he refers to a common storage unit with a certain quality of QoS service. The actual location of data is managed exclusively at the CCB level. This characteristic also refers to the masking of the storage environment. Among other things, disguises the possibility of independent scale-up and CCBs and server pools and other components of the software and hardware complex. Changes at one level are not tied to another.
Algorithmically, the introduction and release of the virtualized storage of volumes involves a two-way translation of the logic of the LUN (Logical Unit Number) data into physical addresses on specific reservoirs. We are therefore dealing with the support and online processing of a matching table between one and another, otherwise with a metadata set. The block responsible for this procedure is sometimes called a virtualizer and can be organized at different levels of the storage subsystem.